

티스토리 뷰
728x90
반응형
1. 학습 목표
- 데이터 전처리의 중요성과 주요 기술을 이해한다.
- 데이터 전처리 과정(결측치 처리, 데이터 정규화 등)을 배운다.
- 모델 평가 지표(정확도, 정밀도, 재현율 등)를 이해하고 활용한다.
2. 데이터 전처리란?
1) 데이터 전처리의 정의
- 머신러닝 모델의 성능은 입력 데이터의 품질에 크게 의존합니다.
- 데이터 전처리는 데이터를 모델 학습에 적합한 형태로 변환하는 과정을 의미합니다.
2) 데이터 전처리가 중요한 이유
- 결측값이나 이상치가 있는 데이터를 그대로 사용하면 모델 성능이 저하될 수 있음.
- 데이터를 정규화하거나 스케일링하면 학습 속도와 정확도가 개선됨.
3) 데이터 전처리 주요 단계
- 결측값 처리(Missing Values Handling):
- 결측값이 있는 데이터를 보완하거나 제거.
- 방법:
- 평균, 중간값, 최빈값으로 채우기.
- 결측 데이터 삭제.
- 데이터 스케일링(Data Scaling):
- 데이터의 범위를 일정하게 조정.
- 기법:
- 정규화(Normalization): 데이터 값을 0과 1 사이로 조정.
- 표준화(Standardization): 평균이 0, 표준편차가 1이 되도록 조정.
- 이상치 처리(Outlier Handling):
- 이상치가 모델 학습에 미치는 영향을 줄이기.
- 방법:
- 이상치 제거.
- 이상치를 적절한 값으로 대체.
- 데이터 인코딩(Data Encoding):
- 범주형 데이터를 숫자로 변환.
- 기법:
- One-Hot Encoding.
- Label Encoding.
- 데이터 분할(Data Splitting):
- 데이터를 학습용(train)과 테스트용(test)으로 나누기.
- 일반적으로 80:20 또는 70:30 비율로 분할.
반응형
3. 데이터 전처리 실습
Python 실습 코드: 데이터 전처리
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 1. 데이터 로드
data = {'Age': [25, 30, 35, None, 40],
'Salary': [50000, 54000, None, 58000, 60000],
'Purchased': ['Yes', 'No', 'Yes', 'No', 'Yes']}
df = pd.DataFrame(data)
# 2. 결측값 처리
df['Age'].fillna(df['Age'].mean(), inplace=True) # 평균으로 채우기
df['Salary'].fillna(df['Salary'].median(), inplace=True) # 중간값으로 채우기
# 3. 데이터 인코딩
df['Purchased'] = df['Purchased'].map({'Yes': 1, 'No': 0}) # Label Encoding
# 4. 데이터 스케일링
scaler = StandardScaler()
df[['Age', 'Salary']] = scaler.fit_transform(df[['Age', 'Salary']])
# 5. 데이터 분할
X = df[['Age', 'Salary']]
y = df['Purchased']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print("훈련 데이터:\n", X_train)
print("테스트 데이터:\n", X_test)4. 모델 평가란?
1) 모델 평가의 정의
- 모델 평가(Metrics)는 학습된 모델의 성능을 측정하는 지표입니다.
- 데이터의 정확한 예측 능력을 검증하기 위해 사용됩니다.
2) 주요 평가 지표
1. 정확도(Accuracy):
- 전체 데이터 중 올바르게 분류된 데이터의 비율.
- 공식:

2. 정밀도(Precision):
- 모델이 "양성"이라고 예측한 것 중 실제로 양성인 비율.
- 공식:
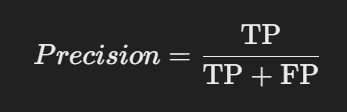
3. 재현율(Recall):
- 실제 "양성" 중 모델이 올바르게 예측한 비율.
- 공식:

4. F1 점수(F1-Score):
- 정밀도와 재현율의 조화 평균.
- 공식:

5. ROC-AUC:
- 모델의 전체적인 분류 성능을 나타내는 곡선 면적.
3) 혼동 행렬(Confusion Matrix)
- 모델의 예측 결과를 시각적으로 표현.
- 구성:
- TP(True Positive): 올바르게 양성을 예측.
- FP(False Positive): 잘못 양성을 예측.
- TN(True Negative): 올바르게 음성을 예측.
- FN(False Negative): 잘못 음성을 예측.
5. 모델 평가 실습
Python 실습 코드: 평가 지표
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix
# 예제 데이터
y_true = [1, 0, 1, 1, 0, 1, 0, 0, 1, 0] # 실제 값
y_pred = [1, 0, 1, 1, 0, 0, 0, 1, 1, 0] # 예측 값
# 평가 지표 계산
accuracy = accuracy_score(y_true, y_pred)
precision = precision_score(y_true, y_pred)
recall = recall_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
print(f"정확도: {accuracy}")
print(f"정밀도: {precision}")
print(f"재현율: {recall}")
print(f"F1 점수: {f1}")
# 혼동 행렬
cm = confusion_matrix(y_true, y_pred)
print("혼동 행렬:\n", cm)6. 복습 질문
- 데이터 전처리가 중요한 이유는 무엇인가요?
- 정규화와 표준화의 차이점은 무엇인가요?
- 모델 평가 지표 중 F1 점수를 사용하는 이유는 무엇인가요?
7. 학습 결과
- 머신러닝 데이터를 학습에 적합한 형태로 준비하는 과정을 이해.
- 결측값 처리, 스케일링, 데이터 분할 등의 전처리 기술을 실습.
- 모델의 성능을 평가하는 주요 지표를 이해하고 활용.
728x90
반응형
LIST
'Study > A.I' 카테고리의 다른 글
| [AI STUDY] 모델 튜닝과 하이퍼파라미터 최적화 (1) | 2025.01.28 |
|---|---|
| [AI STUDY] 딥러닝의 기본 구조와 신경망 구현 (0) | 2025.01.26 |
| [AI STUDY] 머신러닝과 딥러닝의 기초 (1) | 2025.01.20 |
| 생성적 적대 신경망(GAN)은 뭐지? (2) | 2025.01.15 |
| 합성곱 신경망 (CNN)이 뭐지? (1) | 2025.01.15 |
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- 수학초보
- 일차방정식
- 어휘
- Study
- 회화
- 인공지능
- 방정식
- 영어회화
- Ai
- Python
- 영어학습
- 초등수학
- 연립방정식
- 데일리영어
- 학습
- Daily English
- 파이썬
- 선형회기
- 리딩
- 영어공부
- 데일리잉글리쉬
- 초급영어
- 일일영어
- 수학공부
- 연습문제
- 초보영어
- 2차방정식
- 머신러닝
- 영어초보
- 1차방정식
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
글 보관함
반응형